Follow along with Tobias Hrynick, Fordham HASTAC Scholar and medievalist extraordinaire, for an incredibly helpful and detailed Python tutorial! If you want to save this material for a future blizzard weekend, download the PDF version: Hrynick Python Trouble.
1. Introduction
Just as the digital humanities remain to some extent separated from non-digital scholarship (though progress is being made), digital scholarship involving active scripting remains separated from that involving manipulation of pre-programmed consoles. This separation is not a function simply of difficulty: basic scripting is relatively easy, while the manipulation of popular consoles like ArcGIS mapping software or the Omeka content management system can be wildly infuriating. Console-based systems, however, tend to be clearly and obviously oriented to particular purposes – a scholar working with geographical data is likely to persistently run up against Geographic Information Systems, until they finally break down and try to learn one. The sheer number of broadly similar programming languages and the breadth of possible uses for each makes the decision to learn any particular one spring less automatically out of a particular humanities research topic.
Second, and more importantly, scripting languages tend to resist initial attempts at experimental learning. Consoles offer buttons to push. Knowing the right buttons to push is not always easy – but in many senses this doesn’t matter. At first, push all the buttons! Something is bound to happen, and one can combine observations of what these somethings are into some level of working knowledge. Scripting platforms offer no buttons. It is just that typing things in and seeing what happens will not work – pressing random buttons on a console generally won’t work either. It is that initial trial and error in scripting will generally fail in uninteresting ways.
The first problem can be solved simply by a willingness to devote some time to some scripting language, even if you randomly select one from a list, on the assumption that it might be helpful eventually. The odds are in your favor, and the same flexibility which makes the choice between popular scripting languages difficult makes the decision less important. This blog entry is intended to help address the second problem, for the language (*dice rattling*) Python – a flexible programming language which has been particularly popular for text analysis. It is intended to demonstrate some basic Python commands, point out some of the things which Python could be used for, equip readers with and understanding sufficient to make the program fail to work in more interesting ways, and provide some basic vocabulary which will make it easier to search for the answers to problems which arise.
2. Basic Python
In general, it is better to learn Python by trying to solve problems with it. However, trying to do this without some base-level knowledge is more frustrating than enlightening. The following is a very brief and partial description of Python, intended to help you reach the trial-and-error phase with a minimum of psychological trauma.
Python is a system of constructing instructions in a text editor which a computer can understand and carry out. The name is employed in multiple, slightly different ways – it can refer either to the language in which these instructions are written, or more loosely, into the system of software which allows them to be implemented (as in the ever-popular remark, “Python just did something weird…”).
Using Python on your computer will require two different programs. The first is a plain-text editor for writing instructions: this can be any text editor already on your machine, but it is probably easier at first to download a text editor specifically designed to facilitate the creation of Python code. The second necessary program is an interpreter (or shell) – this lets the computer understand and execute the instructions you give it. Both of these can be downloaded together – many other versions exist, but IDLE version is fairly user-friendly, popular (a boon for finding tutorials), and provides a good common point of reference.
It is also important to know that there are several versions of Python which are active, with a basic division between Python 2 and 3. 3 is likely to become increasingly popular eventually, but because it is not backwards-compatible with 2, many users have been reluctant to change. The continuing preference for 2 means that the resources available online for learning 2 are generally better, which is a strong argument in favor of the older system for a beginner. Information here is for Python 2 (2.7 specifically).
Once you install a version of IDLE, open it and you will be brought to the Python shell. From here, you can run longer scripts, or you can enter single commands, and see how Python evaluates them one step at a time.

3. Data Types
Python is structured around data elements which can all be manipulated in broadly similar ways. However, Python data exist in a number of different classes, which affects some of the particular operations which can be conducted with them. The following are some of the most important types:
- int (integer): Integers are positive, negative, or zero whole-number values. These can be manipulated using ordinary mathematical operators (like +, -, *, and /), but any operation which would render a non-whole number will be given as a truncated whole number value (so 3/2 becomes 1). Another useful operator is %, which will output the remainder of a division (so 4%2 outputs 0, while 5%2 outputs 1).
- float (floating point number): A more precise kind of number, though still not a perfectly exact one. Python will understand 3.0 or 4.987876890 as floating point numbers, and will perform division rendering a decimal answer which is adequately precise for the vast majority of uses.
- str (string): A series of symbols, understood as symbols rather than as any content they might convey. Python understands as strings symbols which are enclosed in either single or double quotation marks. “1,” would be a string, as would the entire text of Hamlet, so long as it was enclosed in quotation marks, but 1, with no quotes, would be understood as an integer.
- list: a meta-set of data elements, signified by square brackets, with items within it separated with commas, as in [1, “fred”, 3.14, [1, 2, 3], “zebra”]. As shown in the example, the items within a list can be integers, floats, strings, or even other lists. Note that several other broadly list-like classes of data exist: dictionaries and tupples. We will ignore these for the moment, however.
Once you have defined a variable as a list, you can call particular elements from the list, using the command listname[itemnumber], remembering that items within a list are numbered from 0 rather than from 1. So if the example list above were called list1, list1[0] would render 1, list1[1] would render “fred,” and so on. The command len(), with the name of a list within the parentheses, will give the number of elements (length) of the list – len(list1) would give 5.
Commands int(), float(), str(), and list() all exist to convert values to the appropriate type. Try out some commands on shell –“list(‘hello)”, “int(1.3)” “list(str(546+89))” and similar – to try out the limits of these commands. Note, for example, that the int() command is smart enough to convert “1” to 1, but not to convert “one” to 1.
4. Variables
Variables are names to which particular values are assigned. Python will generally interpret any string of characters which is not marked out as one of the types above as a variable name, and will react with a confused error message if you enter such a thing without previously defining it – note the difference between the reaction of the shell when you input a name like “James,” with or without quotation marks.
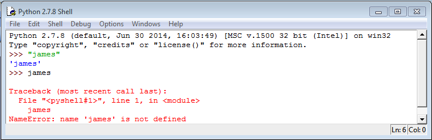
Variables are assigned value using the = sign.
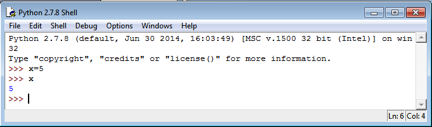
Try assigning values of various types to variables of your choosing, and then having the shell evaluate them by re-entering the name, as above. Note that while you can use number in variable names (ie “variable1”) you cannot have a number alone be the variable name (preventing confusing commands like 1=8).
5. Some More Basic Commands and Operations
- print: The print command causes something within a python script to be displayed to the user. Note the automatic evaluation of variables which occurs in the Python shell does not occur when the shell is running a full script – Python will only display what the script explicitly tells it to. “print ‘x’” will cause python to return “x”. ‘print x,’ will cause Python to return the value of the variable x, if one has been assigned, or to give an error message if one has not.
- input(): The input command prompts the user by printing whatever is contained within the parentheses. The normal way of using this command would be to tie it to a variable, as in “age=input(‘What is your age?)”. A similar command is raw_input(), which will automatically convert the input to a string.
- if: The simplest of Python’s conditional statements. The if-statement evaluates whether a given statement is true or false, and performs the succeeding block of code only if it is true. The condition must be followed by a colon, and all the things which are carried out only if the statement is true must be indented. The indentation can be done either with spaces or tabs, but all indented elements must be indented the same amount.
There are several ways of making statements which Python can evaluate to be true or false. The simplest way is a numerical evaluation, using one of the following operators
== is equal to (distinguished from a single = which declares a variable equal to
something, rather than checking if it is or not)
< is less than
> is greater than
<= is less than or equal to
>= is greater than or equal to
!= is not equal to
So, a simple section of script might run:

If you want to try running this script, by the way, select “new file,” from the file menu on the top of your Python shell, enter the text of the script in the text editor window which opens, save the file, and click “run module,” on the “run,” menu.
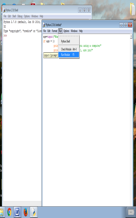
Another useful evaluative operation, relevant to lists is the command “in,” which tests whether a given data element is in a particular list. For instance, a program which tested if a letter were upper case might run – not that the script also demonstrates the use of an else, statement, which allows you to create a block of code which will activate only if the if-statement is not true.

Note that lists can be spaced out over multiple lines like this if it is more convenient, though they may also be put on a single line – the commas are necessary in either case.
The preceding information is relatively bare-bones. However, it is already enough to do a great deal. The following section will illustrate a problem which can be solved entirely using the above commands. Some descriptions of commands will be reiterated in the narrative below, as reminders, but you may want to refer back up to this section if you are having difficulty understanding particular commands.
6. Sample Program
Note: Commentary in this section will be written in blue to distinguish it from code.
Let us suppose that you wanted to have a program that could rapidly translate between Centigrade and Fahrenheit degrees of temperature. How could you go about this, using the above commands (bearing in mind that the relevant equation is C=(5/9)(F-32). If you are feeling reasonably confident about the information above, try scripting your own. If you would rather not try that yet, look through the script below and see if you can follow it.
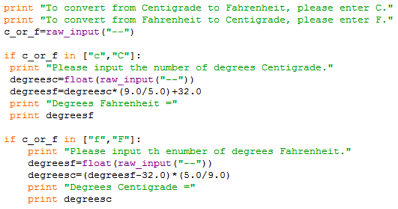
In case you were having trouble following that, let’s go through it again section by section.

Here, we are printing out instructions for the user, and requesting a user input which we will store in the variable “corf,” which the program can later use to determine which conversion it needs to make. We use the “raw_input()” command to ensure that the input will be treated as a string.
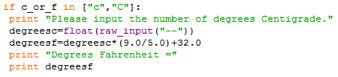
The if-statement in the first line tests to see if the user input was either “c” or “C” – it is good to check both upper and lower case because Python is case sensitive, and users are unpredictable. The second line prints an instruction for the user to input a number of degrees, which the third line prompts for, and stores in the variable “degreesc.” This line also uses the command float() around the raw_input() command, to convert the input from a string into a floating point number.
The forth line, “degreesf=degreesc*(9.0/5.0)+32.0 calculates the equivalent value in degrees Fahrenheit of the input in degrees Centigrade. It is important to include the “.0” for the numbers, because Python interprets whole numbers without “.0” as integers, which Python divides by truncating all the numbers after the decimal point (so that 9/5 would yield 1, which would throw off the value considerably).
The final two lines print first and identifier (“Degrees Fahrenheit=”) for the users benefit, and then the actual value in degrees Fahrenheit, which the program earlier stored in the variable “degreesf.”
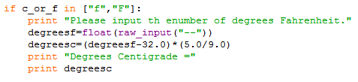
The second block of code does for the choice of Fahrenheit to Centigrade exactly what the first block did for the choice of Centigrade to Fahrenheit. This kind of repetition with slight variation is extremely common across many kinds of script.
7. Going Forward
Get all that? Well, if you have never looked at a Python script before, maybe not. But that’s fine. With luck, you will have gotten enough to start messing around, if you want to. If you do, here are a couple of problems which you might try to solve, to get used to the language.
- Try to modify the above script, or write a whole new script, which can also handle conversions to and from degrees Kelvin.
- At the moment, if a careless or malicious user entered a letter other than C or F in the above script, the program would simply fail to respond. Try to modify the above script to produce an error message if this occurs.
- Try to write a script which can convert between meters, centimeters, feet, and inches.
Or, better still, just do something else entirely, even if it is wholly trivial. Once you can use a scripting language to solve trivial problems, it is only a matter of time before you start using it to solve significant ones, and shifting from strictly mathematical manipulation to manipulation with greater applicability for the study of the humanities.
Thanks to Renee and Steve Symonds for programming advice on aspects of this entry – readers may be assured that the errors, however, are entirely mine.
Blog Post By: Tobias Hrynick, HASTAC Scholar